No products in the cart
COVIDMEX: EXPLORANDO LOS DATOS ESTANDARIZADOS DE LOS PUBLICADOS POR LA SECRETARÍA DE SALUD

Esta entrada de blog está inspirada en la anterior titulada COVIDMEX: DATOS ABIERTOS ESTANDARIZADOS ACERCA DE LA PROPAGACIÓN DEL CORONAVIRUS EN MÉXICO, en la cual el IICD® comunicó la relevancia del sitio CovidMex, durante la evolución de esta contingencia sanitaria ocasionada por el virus Covid-19.
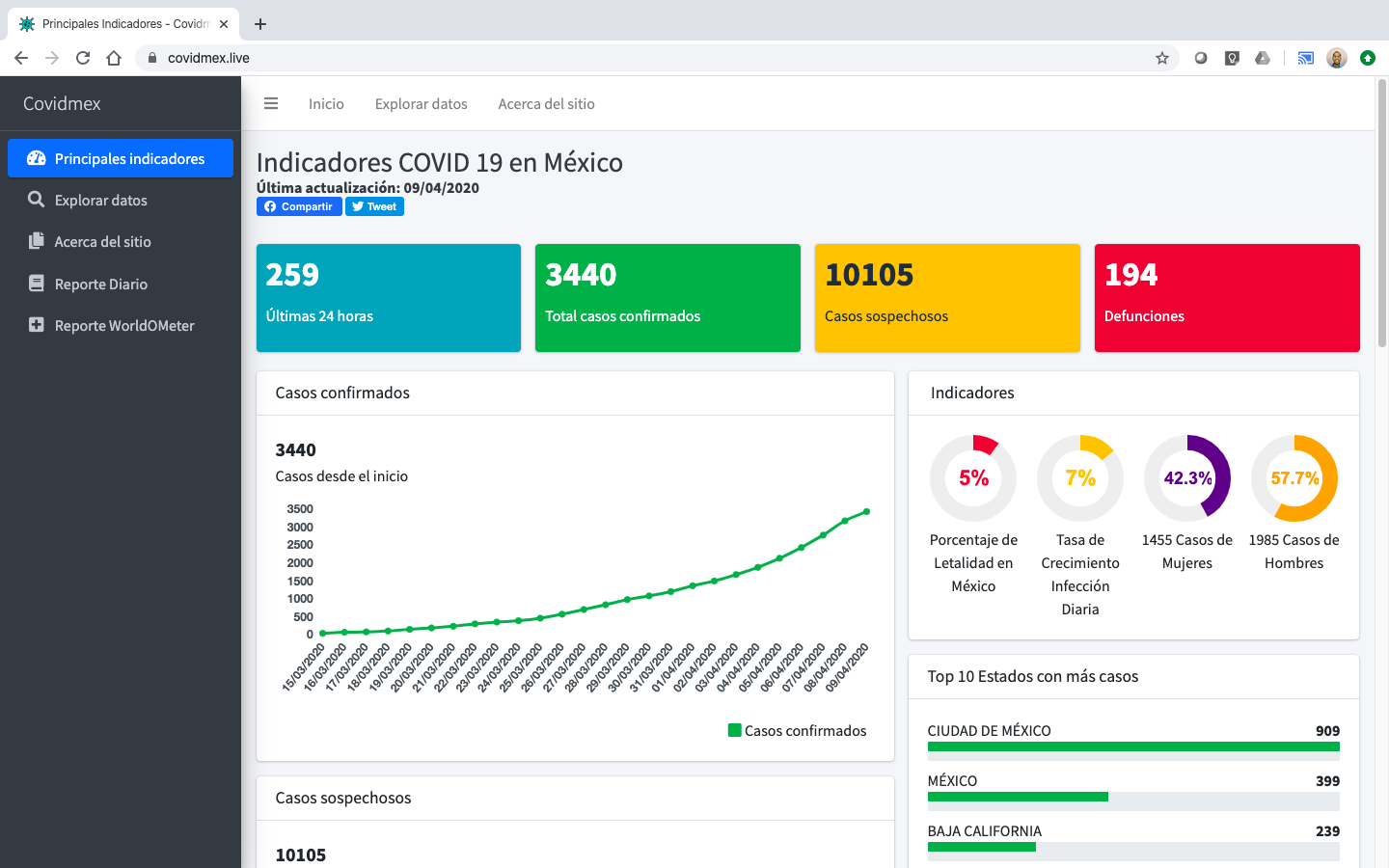
El objetivo en ésta es motivar a la sociedad a realizar el análisis de los datos estandarizados y disponibles en el sitio de CovidMex. Para tal propósito, se realiza una comparación de cómo son disponibilizados los datos en la Secretaría de Salud Pública, y cómo son estandarizados en CovidMex. Al final, se listan algunas preguntas que pueden ser respondidas con estos datos, y algunas otras consideraciones.
¿En qué formato están los datos de evolución del coronavirus en el sitio CovidMex?
¿En qué formato están los datos de evolución del coronavirus en el sitio CovidMex?
Hay tres formatos en los que puedes descargar los datos: (1) CSV, (2) JSON y (3) MySQL.

El primer formato, CSV, corresponde a un archivo separado por comas. Es el formato más sencillo y rápido para cargar en cualquier herramienta de análisis de datos. El segundo corresponde a un estándar para almacenar datos estructurados y semi-estructurados (JSON), y el tercero, corresponde a la base de datos abierta y open source MySQL.
En esta exploración utilizaremos el primero, CSV, por sus características de usabilidad para la mayoría de personas. También presentaremos parcialmente, debido a la cantidad de registros, los archivos utilizando Microsoft Excel.
¿A qué información acerca del coronavirus tengo acceso al descargar los datos del sitio CovidMex?
¿A qué información acerca del coronavirus tengo acceso al descargar los datos del sitio CovidMex?
Una vez que has realizado la descarga, tendrás en tu equipo de cómputo 5 archivos CSV con las siguientes características:
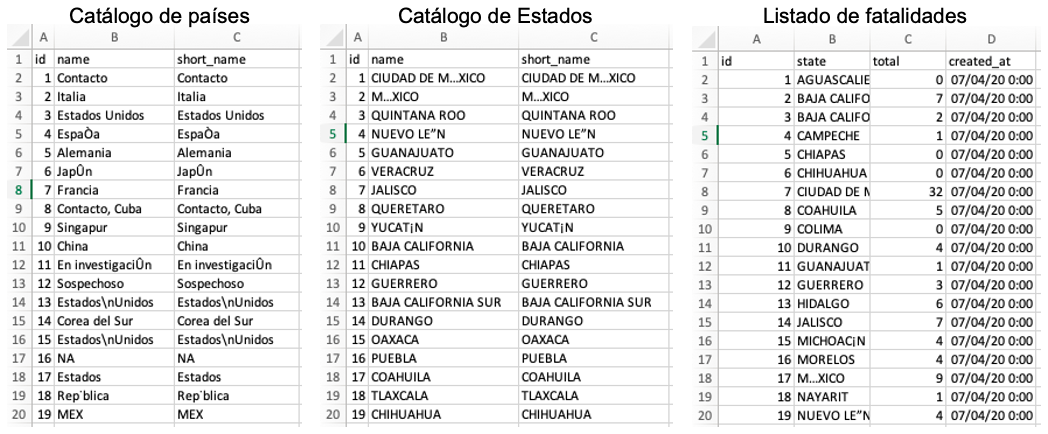
- Catálogo de países: Archivo con el nombre de más de 60 países. Este catálogo se utiliza para estandarizar e indicar el país de procedencia de las personas confirmadas y sospechosas de portar el virus. Este archivo es clave, dado que garantiza que todo los países siempre tienen el mismo nombre, en los diferentes reportes diarios publicados por la Secretaría.
- Catálogo de estados: Similar al anterior, pero con el nombre estándar de cada uno de los Estados de México. Garantiza la estandarización de nombres de Estados en un reporte diario y otro.
- Listado de fatalidades: Defunciones ocurridas en cada estado y por fecha de ocurrencia. Este listado se extrae directamente del documento PDF, que contiene el mapa presentado diariamente en televisión, por el Subsecretario Hugo López-Gatell Ramírez.
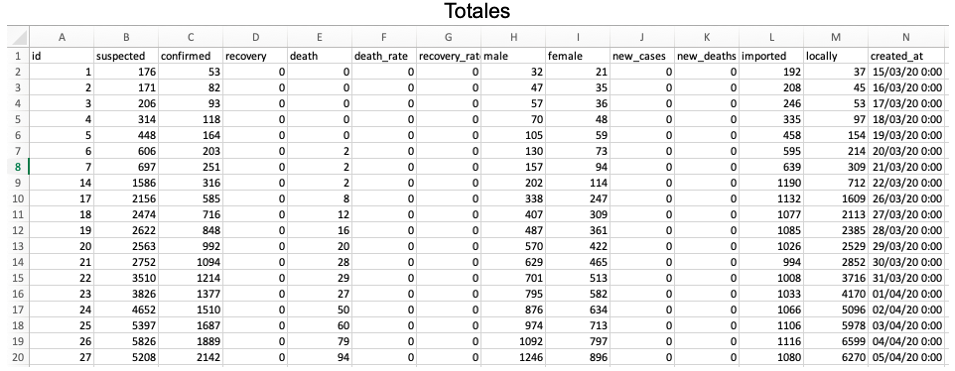
- Totales: Contiene un agregado a nivel diario y por género de la cantidad acumulada de los casos sospechosos, confirmados y decesos. También se especifica si los casos confirmados corresponden a casos importados provenientes del extranjero. Esta es una tabla resumen generada automáticamente por CovidMex, y que con el formato de publicación de la Secretaría de Salud, tomaría mucho tiempo generarla.
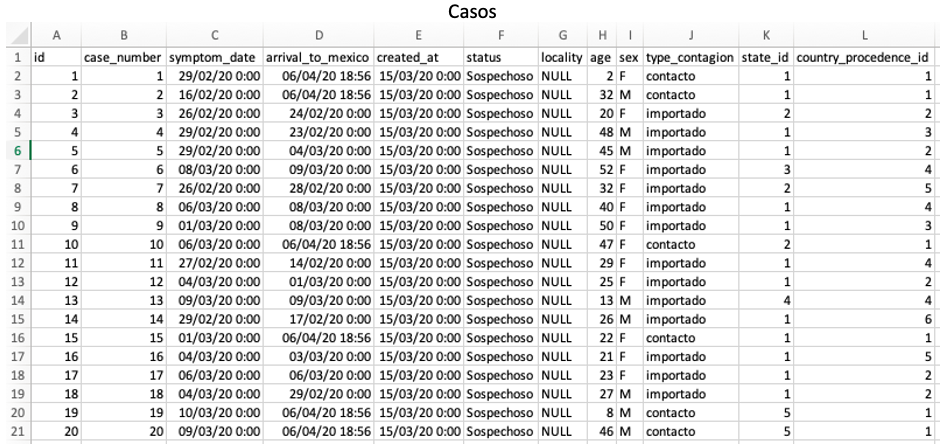
- Casos: Relación de todos los casos tanto sospechosos como confirmados a nivel estatal, género, edad, tipo de contagio, fecha en que empezaron a sentirse los síntomas, y fecha de alta en el reporte de la Secretaría de Salud. El país y estado de procedencia se obtiene de los catálogos descritos en los archivos CSV números 1 y 2.
Los 5 archivos CSV anteriores son generados a partir de los siguientes tres documentos PDFs publicados diariamente por la Secretaría de Salud Pública aquí. Entre los tres suman más de 250 páginas a la fecha de redacción de esta entrada.
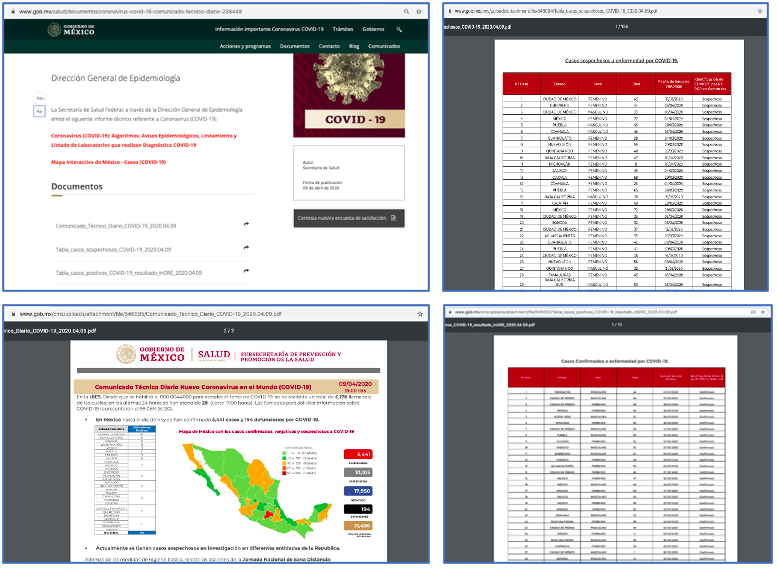
¿Cómo CovidMex convierte automáticamente los tres documentos PDF anteriores en archivos tabulados y estandarizados?
¿Cómo CovidMex convierte automáticamente los tres documentos PDF anteriores en archivos tabulados y estandarizados?
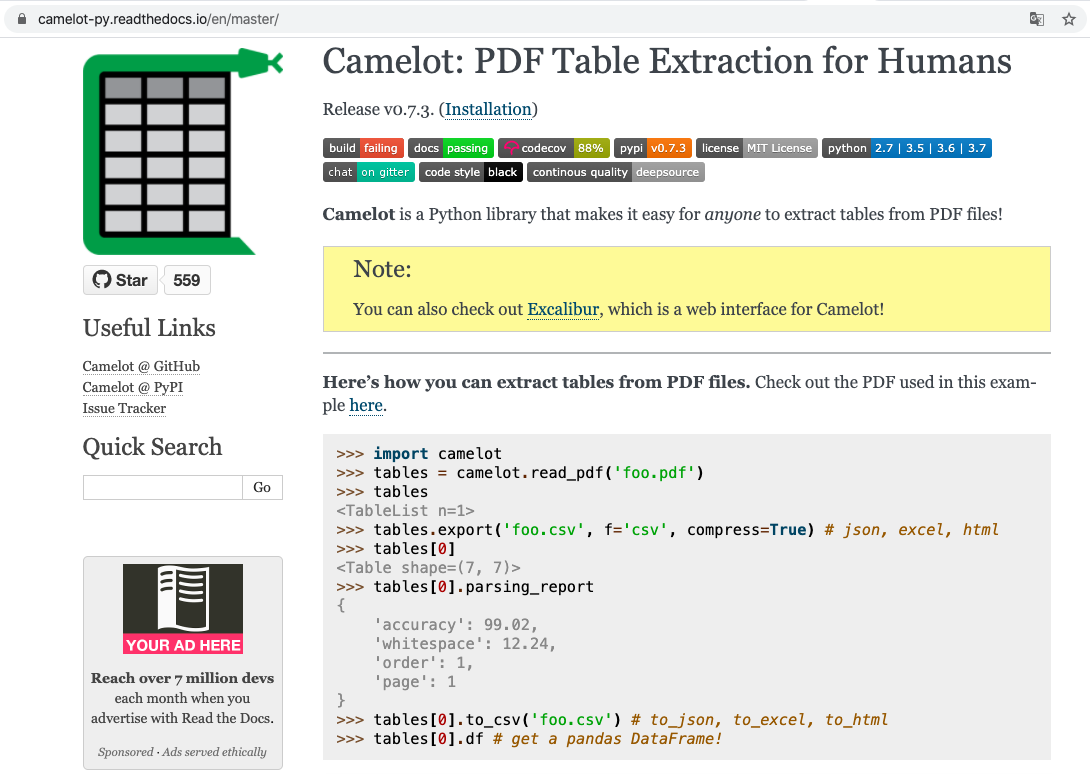
La magia detrás de CovidMex se encuentra en la utilización de Camelot, una librería del lenguaje de programación Python que permite extraer tablas de datos plasmadas en documentos PDFs. Camelot es una librería muy útil, porque que cuando se copia y pegan tablas copiadas desde documentos PDFs, las características de las tablas no se conservan cuando éstas son pegadas en otras aplicaciones (cantidad de columnas, filas, campos, registros, tipo de texto numérico, entre otras).
Una vez que CovidMex extrae las tablas de los documentos PDFs mostrados arriba, éstas se almacenan en formato JSON, luego otra librería de nombre SQLAlquemy, las almacena en una base de datos MySQL, y finalmente, desde esta última, se generan los archivos en formato CSV.
Con los tres pasos anteriores se logra una mezcla de 95% del proceso completamente automatizado, y un 5% de manual. La parte manual es básicamente lanzar el proceso automático una vez que la Secretaría publica los documentos PDFs, y si es el caso, ante un cambio de formato es necesario modificar manualmente parte del código Python.
¿Qué preguntas se podrían responder acerca de la evolución del coronavirus con estos datos?
¿Qué preguntas se podrían responder acerca de la evolución del coronavirus con estos datos?
Las siguientes son algunas preguntas a las que se le puede dar respuesta con los datos de la Secretaría de Salud Pública:
- ¿Cuál es la evolución diaria de la cantidad de personas confirmadas y sospechosas de contraer el virus a nivel estatal?
- ¿Qué género es más propenso a contraer el virus, las personas de género femenino o masculino?
- ¿De qué estado son las personas que han fallecido como consecuencia de haber contraído el coronavirus?
- ¿Cómo es la evaluación de confirmados, sospechosos y decesos en México en comparación con otros países?
A pesar del esfuerzo relevante realizado por Guillermo Alvarado, Francisco Araya y César Montedonico, la preguntas que se pueden responder con los datos publicados por la Secretaría de Salud pública, son preguntas de poca profundidad. Lo anterior debido a la manera como están relacionados los datos publicados por la Secretaría.
¿Se te ocurre alguna otra pregunta de interés que se pueda resolver con los datos de la Secretaría?
Coméntanos y prometemos dar una respuesta a la misma.
En los próximos días, estaremos publicando otras entradas respondiendo preguntas de interés como las listadas en el tercer apartado de esta entrada; y también, estaremos realizando un análisis de cómo se podría mejorar la estructura de los datos para poder responder preguntas de mayor profundidad y de relevancia social.
Trackbacks/Pingbacks