No products in the cart
BIG DATA: EXTRAER, TRANSFORMAR Y CARGAR LOS DATOS
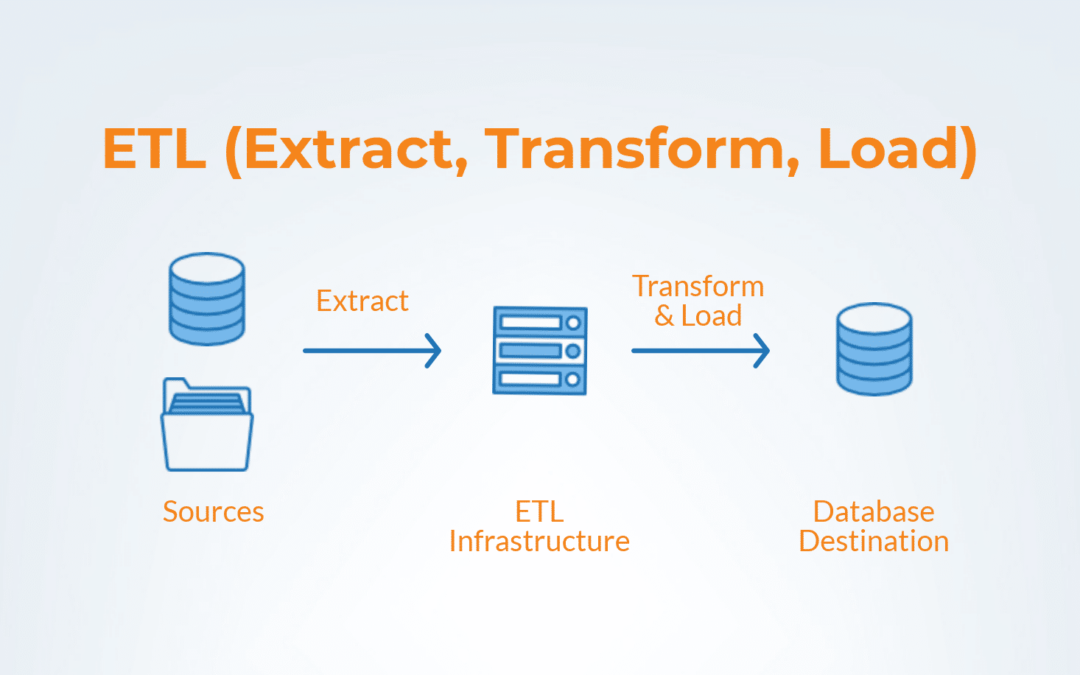
En los últimos años, las organizaciones de todos los sectores públicos y privados han tomado la decisión estratégica de convertir los datos del Big Data en una ventaja competitiva. El reto de extraer valor de las grandes cantidades de datos es similar en muchos aspectos al viejo problema de la destilación de la inteligencia de negocios a partir de datos transaccionales. El corazón de este desafío es el proceso que se utiliza para extraer datos desde múltiples fuentes, transformarlos para satisfacer las necesidades analíticas y cargarlos en un almacén de datos para su posterior análisis, un proceso conocido como Extraer, Transformar y Cargar (ETL). La naturaleza del Big Data requiere que la infraestructura para este proceso se pueda escalar de forma rentable.
Las soluciones de software ETL combinan estas tres funciones importantes (extracción, transformación y carga), para obtener los datos de un entorno de datos muy grande y habilitarlos en otro entorno. Tradicionalmente, el ETL ha sido utilizado con el procesamiento por lotes en ambientes de almacenamiento de datos (Data Warehouse). Los almacenes de datos ofrecen a los usuarios de negocio una manera de consolidar la información para analizar y reportar sobre datos pertinentes a su enfoque de negocio.
Las herramientas ETL se utilizan para transformar los datos en el formato requerido. La transformación se realiza en realidad en una posición intermedia antes que los datos sean cargados en su destino final. Muchos proveedores de software como IBM, Informática, Pervasive, Talend y Pentaho, proveen soluciones ETL.
El ETL proporciona la infraestructura subyacente para la integración mediante la realización de las tres funciones previamente expuestas:
Extraer: Colecta datos de múltiples fuentes de datos y en múltiples formatos como archivos planos y archivos XML. Puede existir la necesidad de recopilar datos de sistemas heredados que almacenan datos en formatos arcaicos poco utilizados. Esto suena fácil, pero puede de hecho ser uno de los principales obstáculos en poner en marcha un ETL.
Transformar: Convertir el formato de los datos extraídos para que se ajuste a los requisitos de la base de datos de destino. La transformación se lleva a cabo mediante el uso de reglas o la fusión de datos. Este paso puede incluir múltiples manipulaciones como mover, dividir, traducir, fusionar, ordenar, clasificar y más.
Carga: Escribe los datos en la base de datos destino tradicionalmente en procesos batch.
Sin embargo, el ETL está evolucionando para apoyar la integración a través de mucho más que los almacenes de datos tradicionales. Puede apoyar la integración en los sistemas transaccionales, bases de datos operativos, plataformas de BI, hubs MDM (Master Data Management), la nube y plataformas de Hadoop. Proveedores de software ETL están ampliando sus soluciones para ofertar la extracción de grandes volúmenes de datos, transformación y carga entre Hadoop y plataformas tradicionales de gestión de datos.
El ETL y herramientas de software de otros procesos de integración de datos como la limpieza de datos, el perfilado y la auditoria, trabajan en forma conjunta para asegurar que los datos sean considerados como confiables. Herramientas de ETL se integran con herramientas de calidad de datos y muchos incorporan herramientas para el mapeo e identificación de linaje de datos. Con el ETL, sólo se extraen los datos que se van a necesitar para la integración.
Se necesita el ETL para la carga y conversión de datos estructurados y no estructurados en Hadoop. Herramientas avanzadas de ETL pueden leer y escribir archivos múltiples paralelamente desde y hasta Hadoop para simplificar cómo los datos se fusionan en un proceso de transformación común. Algunas soluciones incorporan bibliotecas de transformaciones ETL prediseñados, tanto para la transacción como para la interacción de datos que se ejecutan en Hadoop o en una infraestructura de red tradicional.
La transformación de datos es el proceso de cambiar el formato de los datos de modo que puedan ser utilizados por diferentes aplicaciones. Esto puede significar un cambio en el formato de los datos almacenados en un formato que necesita la aplicación que los utilizará. Este proceso también incluye las instrucciones de mapeo, de tal manera que a las aplicaciones se les dice cómo obtener los datos que necesitan para procesar.
El proceso de transformación de datos se hace mucho más complejo debido al asombroso crecimiento en la cantidad de datos no estructurados. Cuando el universo de datos es dramáticamente grande y no estructurado, el ETL tradicional puede convertirse en un cuello de botella, porque es demasiado complejo para ser implementado, excesivamente costoso de operar y el desempeño se puede ver degradado en forma significativa.
Una solución de negocios, tal como el CRM que gestiona la relación con los clientes, tiene requisitos específicos de cómo los datos deben ser almacenados. Los datos son susceptibles de ser estructurados si pueden ser organizados en forma de filas o columnas en una base de datos relacional. Los datos son semi-estructurados o no estructurados si no siguen los requisitos de un formato rígido.
La información contenida en un mensaje de correo electrónico se considera como no estructurado, por ejemplo. Alguna de la información más importante de una empresa está en forma no estructurada y semi-estructurada. Ejemplo de ello son documentos, mensajes de correo electrónico, las interacciones de soporte al cliente, las transacciones y la información procedentes de aplicaciones empaquetadas como el ERP o el CRM.
Herramientas de transformación de datos no están diseñados para trabajar adecuadamente con datos no estructurados. Como resultado, las compañías que necesitan incorporar información no estructurada en la toma de decisiones de procesos de negocio, se han enfrentado a una cantidad significativa de codificación manual para lograr la integración de los datos requeridos.
Teniendo en cuenta el crecimiento y la importancia de los datos no estructurados para la toma de decisiones, las soluciones ETL de los principales proveedores están comenzando a ofrecer enfoques estandarizados para transformar los datos no estructurados de forma que puedan ser más fácilmente integrados con datos estructurados operacionales. Este finalmente es el reto más importante al que las soluciones de ETL se enfrentan para la adopción del Big Data.